Strings Obfuscation System
A string obfuscation system that integrates in a Visual Studio C++ solution
Michael Haephrati, CodeProject MVP 2013
Download source code - 16 KB
Introduction
The purpose of obfuscators in general is to hide program code, flow, and functionality. If your program uses an algorithm that is a trade secret, obfuscation will make it harder to reverse engineer it and reveal this trade secret. But what about hiding the data inside the executable? Some people say that is almost impossible to achieve. Since the problem needs to be able to read this data, the data must be there, and if it is there, it can be revealed eventually. In my opinion, a well obfuscated program, can make it next to impossible to guess where the data is kept (encrypted), and even if the data is found, to obfuscate it using strong encryption.
The Solution
The set of tools I will introduce in this article, were developed for the purpose of encrypting strings within applications.
Usually, an application can reveal a great deal of information about itself, even without having to reverse engineer it. When you open an application such as Calc.exe from a Hex editor (or from Notepad as a text editor), you can find strings like:
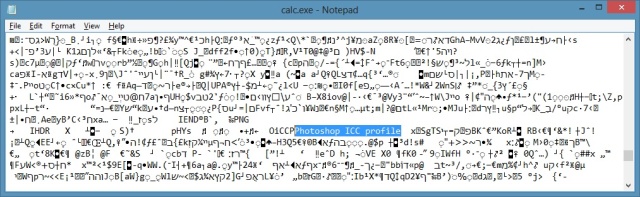
An example of strings that create a risk if kept non encrypted, is passwords. If your software connects to an Internet service, SMS gateway or a FTP server, and send a password, this password will be visible to anyone who opens the executable of your application with any textual editor.
Background
I have read Chris Losinger's excellent article and wanted to take it to the next level by creating a stronger encryption (AES-256) and to support more variations and string types, including UNICODE, double and single byte strings.
The purpose of this tool is professional use, and not just being a proof of concept.
The Source Code
The encryption / decryption mechanism integrate as two separate projects which need to be added to your Visual Studio solution. The two projects are in the main folder:
a. The obfisider project.
b. The obfuscase project.
The Obfisider and the Obfuscate Projects
The Obfisider project contains the AES encryption part. The Obfuscate project contains the necessary parts to scan a solution, and each project it contains, and to encrypt the strings found.
Scanning a SolutionSolutions are scanned using parseSolution which calls another function named parseProject .
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45static strList parseSolution( const char * solName ) { strList result; static char drive[_MAX_DRIVE]; static char somepath[_MAX_PATH]; static char buffer[_MAX_PATH]; static char path[_MAX_PATH]; static char ext[_MAX_EXT]; _splitpath( solName, drive, somepath, buffer, ext ); FILE * f = fopen( solName, "r" ); if( NULL == f ) { printf("ERROR: Solution %s is missing or unavailable.\n", solName ); exit(1); } while( !feof(f) ) { char * res = fgets( buffer, sizeof(buffer), f ); if( NULL == res ) continue; if( NULL != strstr(buffer, "Project(") ) { char * ptrName = strchr( buffer, '=' ); char * ptrFile = strchr( ptrName, ',' ); *ptrFile++ = 0; char * ptrEnd = strchr( ptrFile, ',' ); *ptrEnd++ = 0; while( ('=' == *ptrName) ||(' ' == *ptrName) ||('"' == *ptrName) ) ptrName++; if( '"' == ptrName[strlen(ptrName)-1] ) ptrName[strlen(ptrName)-1] = 0; while( (' ' == *ptrFile) ||('"' == *ptrFile) ) ptrFile++; if( '"' == ptrFile[strlen(ptrFile)-1] ) ptrFile[strlen(ptrFile)-1] = 0; _makepath( path, drive, somepath, ptrFile, NULL ); result.push_back( std::string(path) ); } } fclose(f); return result; }
The parseProject function extract the relevant files from a given project. Relevant files means : .c, .cpp, .h and .hpp files.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43/** * Parse project and extract fullpath source filename from project. */ static strList parseProject( const char * projName ) { strList result; static char drive[_MAX_DRIVE]; static char somepath[_MAX_PATH]; static char buffer[_MAX_PATH]; static char path[_MAX_PATH]; static char ext[_MAX_EXT]; _splitpath( projName, drive, somepath, buffer, ext ); FILE * f = fopen( projName, "r" ); if( NULL == f ) { printf("ERROR: Project %s is missing or unavailable.\n", projName ); exit(1); } while( !feof(f) ) { char * res = fgets( buffer, sizeof(buffer), f ); if( NULL == res ) continue; if( (NULL != strstr(buffer, "<ClInclude Include=")) ||(NULL != strstr(buffer, "<ClCompile Include=")) ) { char * ptrName = strchr( buffer, '=' ); char * ptrName1 = strstr( buffer, "/>" ); if( NULL != ptrName1 ) *ptrName1 = 0; while( ('=' == *ptrName) ||(' ' == *ptrName) ||('"' == *ptrName) ) ptrName++; while( ('"' == ptrName[strlen(ptrName)-1]) ||(' ' == ptrName[strlen(ptrName)-1]) ||('\n' == ptrName[strlen(ptrName)-1])) ptrName[strlen(ptrName)-1] = 0; _makepath( path, drive, somepath, ptrName, NULL ); result.push_back( std::string(path) ); } } fclose(f); return result; }
The AES_Encode function
This function handles the encryption of the strings using AES-256:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36/* -------------------------------------------------------------------------- */ int AES_encode_a( unsigned int key_start, const wchar_t * plainString, unsigned char * outbuf, unsigned outlen ) { unsigned char key[32]; aes_key key_context = {0}; int i; unsigned char offset; /** Calculate required size */ int retval = (wcslen(plainString) + 1); /** Round to 16 byte over */ retval = ((retval + 15)&(~0xF)) + 4; /** Memory request */ if( NULL == outbuf ) return -retval; /** Not enought memory */ if( outlen < retval ) return 0; /** Prepare output buffer */ memset( outbuf, 0, retval ); // wcscpy( (char*)(outbuf+4), plainString ); WideCharToMultiByte( CP_ACP, 0, plainString, -1, (outbuf+4), retval-sizeof(unsigned),NULL, NULL); *((unsigned*)outbuf) = key_start; /** Prepare key */ srand(key_start); for( i = 0; i < sizeof(key); i++ ) key[i] = rand(); aes_prepare( &key_context, key ); memset( key, 0, sizeof(key) ); for( i = 4; i < retval; i += 16 ) { aes_encrypt_block( &key_context, &outbuf[i] ); } memset( &key_context, 0, sizeof(key_context) ); return retval; } /* -------------------------------------------------------------------------- */
The AES_Decode function
This function handles the decryption of the strings back:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25/* -------------------------------------------------------------------------- */ static int AES_decode( const unsigned char * inbuf, unsigned inlen, void *plainString, unsigned stringSize ) { unsigned char key[32]; aes_key key_context = {0}; int i; BYTE * outbuf = (BYTE*)plainString; if( NULL == plainString ) return -inlen; if( stringSize < inlen ) return 0; /** Prepare output buffer */ memcpy( outbuf, inbuf, inlen ); /** Prepare key */ for( i = 0; i < sizeof(key); i++ ) key[i] = rand(); aes_prepare( &key_context, key ); memset( key, 0, sizeof(key) ); for( i = 0; i < inlen; i += 16 ) { aes_decrypt_block( &key_context, &outbuf[i] ); } memset( &key_context, 0, sizeof(key_context) ); return inlen; }
Decoding the strings back
ASCII strings are decoded using the following function ( __ODA__ ):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24/* -------------------------------------------------------------------------- */ char* __ODA__( const char * enc_str ) { int i, size = strlen( enc_str )/2; unsigned char * inBuff = NULL; unsigned key = 0; PDECODED_LIST ptr = &charList; char * result = a_text_err; while( NULL != ptr->next ) { if( ptr->org_str == enc_str ) return ((char*)ptr+sizeof(DECODED_LIST)); ptr = ptr->next; } if( NULL == (inBuff = (unsigned char*)malloc( size )) ) return result; // a_text_error if( NULL == (ptr->next = (PDECODED_LIST)malloc( size + sizeof(DECODED_LIST) )) ) { free( inBuff ); return result; // a_text_error } ptr = ptr->next; ptr->
When the string is UNICODE, the following function (__ODC__) is used:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24/* -------------------------------------------------------------------------- */ wchar_t* __ODC__( const char * enc_str ) { int i, size = strlen( enc_str )/2; unsigned char * inBuff = NULL; unsigned key = 0; PDECODED_LIST ptr = &wcharList; wchar_t * result = w_text_err; while( NULL != ptr->next ) { if( ptr->org_str == enc_str ) return (wchar_t*) ((char*)ptr+sizeof(DECODED_LIST)); ptr = ptr->next; } if( NULL == (inBuff = (unsigned char*)malloc( size )) ) return result; // w_text_error if( NULL == (ptr->next = (PDECODED_LIST)malloc( size + sizeof(DECODED_LIST) )) ) { free( inBuff ); return result; // w_text_error } ptr = ptr->next; ptr->
How to use
Set project dependencies so the main executable or DLL your solution is generating depends on the "obfinsider" project.
The 'obfinsider' project must depend on the other project – the 'obfuscate' project. This will automatically include obfinsider.lib, but in case you make changes that break this dependency, please add obfisider.lib manually.
How it works
The Process
'obfuscate' is built first and after build is completed, a Post Build event takes place. The Post Build event calls obfuscate along with the entire solution file as its parameter.
The Files ScanObfuscate scans the given solution and works on each relevant file in it. The current version requires that no spaces will exist in this path, and if there are spaces, the proper way "obfuscate" should be called would be:
"$(TargetPath)" "$(SolutionPath)"
"obfuscate" scans the solution for all project files, but process the following file types: .c, .cpp, .h and .hpp.
The Work
Per each file, the following checks are made:
a. Obfuscated files are skipped
b."obfuscate" doesn't process itself, so its own files are skipped.
c. Comments are skipped. This includes:
// this is a commentand
/* this a another comment */d.#include and #pragma declarations are skipped.
e.Initialized global strings are ignored. If you look at the following example:
Static char c[]="test string";f. For all other strings, "obfuscate" looks for the original declaration and replaces it with a calls to the decryption function, along with the encrypted string as its parameter.
For easy maintenance, the original line is preserves as kept as a commented line above the new line.
ASCII vs. Unicode
The system distinguishes between ASCII and Unicode text. Two separate sets of functions are used per each type.
The following statement:
wcscpy(mystring, "my text");or
wcscpy(mystring, _T("my text"));will be detected as Unicode type and will be replaced with a call to __ODC__ while similar ASCII statements:
strcpy(mystring, "my text");
will be detected as such as will be replaced with a call to __ODA__.
Encryption and Encoding Scheme
1. Each string is encrypted separately with an ad-hoc generated encryption key.2. This key is generated randomly, while the SEED value for the random number generated is set at the start of the application.
3. All strings are padded with NULL characters to round them so their length match an entire number of encryption blocked, which are required by the AES-256 encryption scheme.
4. The result, is in a binary form, and is represented as a printable set of characters using the following algorithm:
- Each byte is split by half. Higher half is encoded first and then the 2nd half. For example: 0xAF is split into: 0xA and 0xF.
- The encoded value is the Delta between the preview value and the new value (initial value is "A").
For example: value 0x3 is set as a result of shifting from character "A" and "D" (0x40+0x3==0x43).
5. When the shifted value reaches 0x7E, the initial value of "A" is subtracted from this value.
For example: if Last value was 'z' (code 0x7A) and encoded value is 0xF, then the new value will be encoded as character '+' ( code 0x2B == 0x7A + 0xF - (0x7E-0x20) )Example
The following statement:
wprintf(L"This is a test\n" );
will be replaced with the following lines:
1
2/* wprintf( L"This is a test\n" );*/ wprintf( __ODC__("IPPXXXXXbmm|\"$%.=KXfgpx#-;DPZiw}$$*0=APR[\\epy##$.27EKXXdhq}#/00>DEOVVW]";
Limitations
It is impossible to cover all variations in which strings may appear in a C / C++ project, even though I have done my best to cover most of them. Since one can initialize a one-dimensional character array by specifying:
For example:A brace-enclosed comma-separated list of constants, each of which can be contained in a character A string constant (braces surrounding the constant are optional)
static char a[]="some_string";
When the size of the array is not set, it is impossible to encrypt the predefined contents as the real size isn't know at the time of compilation.
Another example where such system will not be able to encrypt is referred to as "Hidden Merging":
1
2
3#define PRODUCT_NAME "MyProduct" #define PRODUCT_FOLDER "MyFolder" #define WORK_PATH PRODUCT_NAME "/" PRODUCT_FOLDER
License
This article, along with any associated source code and files, is licensed under The Common Development and Distribution License (CDDL)
About the Author
Michael N. Haephrati, is an entrepreneur, inventor and a musician. Haephrati worked on many ventures starting from HarmonySoft, designing Rashumon, the first Graphical Multi-lingual word processor for Amiga computer. During 1995-1996 he worked as a Contractor with Apple at Cupertino. Worked at a research institute made the fist steps developing the credit scoring field in Israel. He founded Target Scoring and developed a credit scoring system named ThiS, based on geographical statistical data, participating VISA CAL, Isracard, Bank Leumi and Bank Discount (Target Scoring, being the VP Business Development of a large Israeli institute).
During 2000, he founded Target Eye, and developed the first remote PC surveillance and monitoring system, named Target Eye.
Other ventures included: Data Cleansing (as part of the DataTune system which was implemented in many organizations.
Follow @haephrati
Follow on Twitter, Google, LinkedIn
Article Top

Attachments: [SourceCode.zip]